遗失的寒冷张亚凌答案:Twitter Search is Now 3x Faster
来源:百度文库 编辑:九乡新闻网 时间:2024/04/27 13:38:08
Twitter Search is Now 3x Faster
In the spring of 2010, the search team at Twitter started to rewriteour search engine in order to serve our ever-growing traffic, improvethe end-user latency and availability of our service, and enable rapiddevelopment of new search features. As part of the effort, we launched anew real-time search engine, changing our back-end from MySQL to a real-time version of Lucene.Last week, we launched a replacement for our Ruby-on-Rails front-end: aJava server we call Blender. We are pleased to announce that thischange has produced a 3x drop in search latencies and will enable us torapidly iterate on search features in the coming months.
PERFORMANCE GAINS
Twitter search is one of the most heavily-trafficked search enginesin the world, serving over one billion queries per day. The week beforewe deployed Blender, the #tsunamiin Japan contributed to a significant increase in query load and arelated spike in search latencies. Following the launch of Blender, our95th percentile latencies were reduced by 3x from 800ms to 250ms and CPUload on our front-end servers was cut in half. We now have the capacityto serve 10x the number of requests per machine. This means we cansupport the same number of requests with fewer servers, reducing ourfront-end service costs.
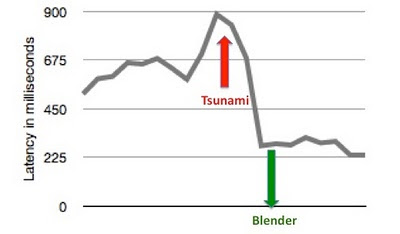
95th Percentile Search API Latencies Before and After Blender Launch
TWITTER’S IMPROVED SEARCH ARCHITECTURE
In order to understand the performance gains, you must firstunderstand the inefficiencies of our former Ruby-on-Rails front-endservers. The front ends ran a fixed number of single-threaded railsworker processes, each of which did the following:
- parsed queries
- queried index servers synchronously
- aggregated and rendered results
We have long known that the model of synchronous request processinguses our CPUs inefficiently. Over time, we had also accrued significanttechnical debt in our Ruby code base, making it hard to add features andimprove the reliability of our search engine. Blender addresses theseissues by:
- Creating a fully asynchronous aggregation service. No thread waits on network I/O to complete.
- Aggregating results from back-end services, for example, the real-time, top tweet, and geo indices.
- Elegantly dealing with dependencies between services. Workflows automatically handle transitive dependencies between back-end services.
The following diagram shows the architecture of Twitter’s searchengine. Queries from the website, API, or internal clients at Twitterare issued to Blender via a hardware load balancer. Blender parses thequery and then issues it to back-end services, using workflows to handledependencies between the services. Finally, results from the servicesare merged and rendered in the appropriate language for the client.

Twitter Search Architecture with Blender
BLENDER OVERVIEW
Blender is a Thrift and HTTP service built on Netty,a highly-scalable NIO client server library written in Java thatenables the development of a variety of protocol servers and clientsquickly and easily. We chose Netty over some of its other competitors,like Mina and Jetty, because it has a cleaner API, better documentationand, more importantly, because several other projects at Twitter areusing this framework. To make Netty work with Thrift, we wrote a simpleThrift codec that decodes the incoming Thrift request from Netty’schannel buffer, when it is read from the socket and encodes the outgoingThrift response, when it is written to the socket.
Netty defines a key abstraction, called a Channel, to encapsulate aconnection to a network socket that provides an interface to do a set ofI/O operations like read, write, connect, and bind. All channel I/Ooperations are asynchronous in nature. This means any I/O call returnsimmediately with a ChannelFuture instance that notifies whether therequested I/O operations succeed, fail, or are canceled.
When a Netty server accepts a new connection, it creates a newchannel pipeline to process it. A channel pipeline is nothing but asequence of channel handlers that implements the business logic neededto process the request. In the next section, we show how Blender mapsthese pipelines to query processing workflows.
WORKFLOW FRAMEWORK
In Blender, a workflow is a set of back-end services withdependencies between them, which must be processed to serve an incomingrequest. Blender automatically resolves dependencies between services,for example, if service A depends on service B, A is queried first andits results are passed to B. It is convenient to represent workflows as directed acyclic graphs (see below).

Sample Blender Workflow with 6 Back-end Services
In the sample workflow above, we have 6 services {s1, s2, s3, s4, s5,s6} with dependencies between them. The directed edge from s3 to s1means that s3 must be called before calling s1 because s1 needs theresults from s3. Given such a workflow, the Blender framework performs atopological sorton the DAG to determine the total ordering of services, which is theorder in which they must be called. The execution order of the aboveworkflow would be {(s3, s4), (s1, s5, s6), (s2)}. This means s3 and s4can be called in parallel in the first batch, and once their responsesare returned, s1, s5, and s6 can be called in parallel in the nextbatch, before finally calling s2.
Once Blender determines the execution order of a workflow, it ismapped to a Netty pipeline. This pipeline is a sequence of handlers thatthe request needs to pass through for processing.
MULTIPLEXING INCOMING REQUESTS
Because workflows are mapped to Netty pipelines in Blender, we neededto route incoming client requests to the appropriate pipeline. Forthis, we built a proxy layer that multiplexes and routes client requeststo pipelines as follows:
- When a remote Thrift client opens a persistent connection to Blender, the proxy layer creates a map of local clients, one for each of the local workflow servers. Note that all local workflow servers are running inside Blender’s JVM process and are instantiated when the Blender process starts.
- When the request arrives at the socket, the proxy layer reads it, figures out which workflow is requested, and routes it to the appropriate workflow server.
- Similarly, when the response arrives from the local workflow server, the proxy reads it and writes the response back to the remote client.
We made use of Netty’s event-driven model to accomplish all the above tasks asynchronously so that no thread waits on I/O.
DISPATCHING BACK-END REQUESTS
Once the query arrives at a workflow pipeline, it passes through thesequence of service handlers as defined by the workflow. Each servicehandler constructs the appropriate back-end request for that query andissues it to the remote server. For example, the real-time servicehandler constructs a realtime search request and issues it to one ormore realtime index servers asynchronously. We are using the twitter commons library (recently open-sourced!) to provide connection-pool management, load-balancing, and dead host detection.
The I/O thread that is processing the query is freed when all theback-end requests have been dispatched. A timer thread checks every fewmilliseconds to see if any of the back-end responses have returned fromremote servers and sets a flag indicating if the request succeeded,timed out, or failed. We maintain one object over the lifetime of thesearch query to manage this type of data.
Successful responses are aggregated and passed to the next batch ofservice handlers in the workflow pipeline. When all responses from thefirst batch have arrived, the second batch of asynchronous requests aremade. This process is repeated until we have completed the workflow orthe workflow’s timeout has elapsed.
As you can see, throughout the execution of a workflow, no threadbusy-waits on I/O. This allows us to efficiently use the CPU on ourBlender machines and handle a large number of concurrent requests. Wealso save on latency as we can execute most requests to back-endservices in parallel.
BLENDER DEPLOYMENT AND FUTURE WORK
To ensure a high quality of service while introducing Blender intoour system, we are using the old Ruby on Rails front-end servers asproxies for routing thrift requests to our Blender cluster. Using theold front-end servers as proxies allows us to provide a consistent userexperience while making significant changes to the underlyingtechnology. In the next phase of our deploy, we will eliminate Ruby onRails entirely from the search stack, connecting users directly toBlender and potentially reducing latencies even further.
—@twittersearch
ACKNOWLEDGEMENTS
The following Twitter engineers worked on Blender: Abhi Khune, AneeshSharma, Brian Larson, Frost Li, Gilad Mishne, Krishna Gade, MichaelBusch, Mike Hayes, Patrick Lok, Raghavendra Prabhu, Sam Luckenbill, TianWang, Yi Zhuang, Zhenghua Li.