金刚在线观看免费:HBase I/O: HFile
来源:百度文库 编辑:九乡新闻网 时间:2024/04/26 07:03:04
HBase I/O: HFile
In thebeginning HBase uses MapFile class to store data persistently to disk,and then (from version 0.20) a new file format is introduced. HFile is aspecific implementation of MapFile with HBase related features.
HFile doesn't know anything about key and value struct/type (row key,qualifier, family, timestamp, …). As Hadoop' SequenceFile(Block-Compressed), keys and values are grouped in blocks, and blockscontains records. Each record has two Int Values that contains KeyLength and Value Length followed by key and value byte-array.
HFile.Writer has only a couple of append overload methods, one forKeyValue class and the other for byte-array type. As for SequenceFile,each key added must be greater than the previous one. If this conditionis not satisfied an IOException() is raised.

By default each 64kof data (key + value) records are squeezed together in a block and theblock is written to the HFile OutputStream with the specifiedcompression, if specified. Compression Algorithm and Block size are both(long)constructor arguments.
One thing thatSequenceFile is not good at, is adding Metadata. Metadata can be addedto SequenceFile just from the constructor, so you need to prepare allyour metadata before creating the Writer.
HFile adds two"metadata" type. One called Meta-Block and the other called FileInfo.Both metadata types are kept in memory until close() is called.
Meta-Block isdesigned to keep large amount of data and its key is a String, whileFileInfo is a simple Map and is preferred for small information and keysand values are both byte-array. Region-server' StoreFile usesMeta-Blocks to store a BloomFilter, and FileInfo for Max SequenceId,Major compaction key and Timerange info.
On close(),Meta-Blocks and FileInfo is written to the OutputStream. To speeduplookups an Index is written for Data-Blocks and Meta-Blocks, Thoseindices contains n records (where n is the number of blocks) with blockinformation (block offset, size and first key).
At the end a FixedFile Trailer is written, this block contains offsets and counts for allthe HFile Indices, HFile Version, Compression Codec and other fewinformation.
Once the file is written, the next step is reading it. You've to start by loading FileInfo, the loadFileInfo() of HFile.Reader loadsin memory the Trailer-block and all the indices, that allows to easilyquery keys. Through the HFileScanner you can seek to a specified key,and iterate over.
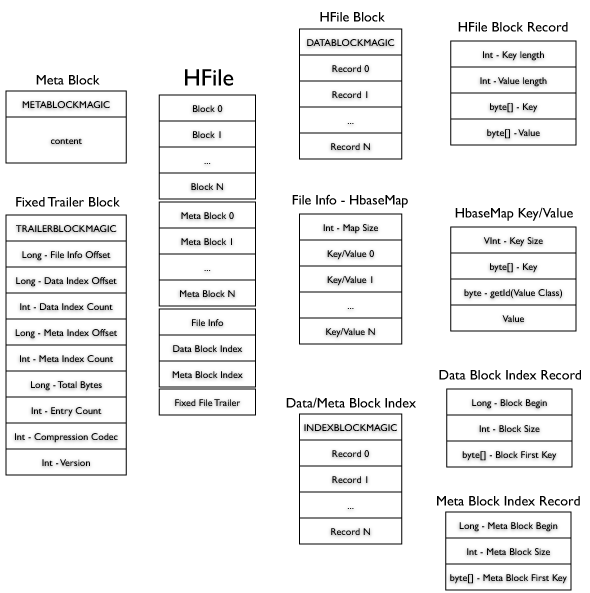 The picture above, describe the internal format of HFile...
The picture above, describe the internal format of HFile...
HBase I/O: HFile
HBase
i/o端口
分布式、远程I/O模块
I/O接口和I/O端口有区别? I/O 接口的作用是什么?
三菱FX2N的I/O扩展
芯片I/O缓冲及ESD电路设计
unix 文件I/O之诠释(三)
阻塞与非阻塞I/O
无缓存I/O操作和标准I/O文件操作区别
同步与异步--阻塞与非阻塞型I/O
用C++进行简单的文件I/O操作
路径,文件,目录,I/O常见操作汇总(一)
路径,文件,目录,I/O常见操作汇总(二)
谷歌2011 I/O大会 Android重大更新详解
使用异步 I/O 大大提高应用程序的性能
磁盘I/O测试工具Bonnie (转贴)
通过 Tomcat Advanced I/O 获得高性能的 Ajax
51--------I/O扩展篇(基于74HC164/74HC165)
从文件 I/O 看 Linux 的虚拟文件系统
Integrating Hive and HBase
Lineland: HBase Architecture 101
HBase存储架构
php操作hbase例子